
Facial Keypoint Detection Using CNN and Autoencoders
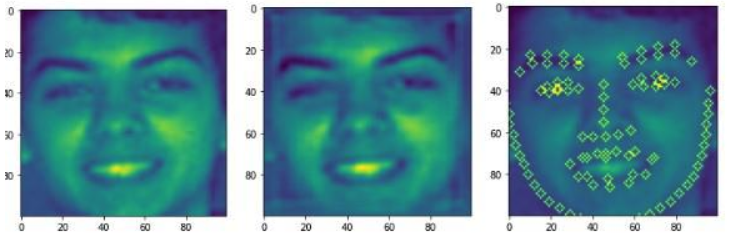
This paper addresses a significant challenge in computer vision: accurately detecting facial keypoints. These are essential for tasks like facial recognition, emotion analysis, and augmented reality, and are crucial in mapping the structure and expressions of human faces.
In this research, you leverage the power of Convolutional Neural Networks (CNNs) and Autoencoders to build an efficient model for detecting facial keypoints. CNNs, widely recognized for their ability to capture spatial hierarchies in images, are employed to extract detailed features from facial images. Autoencoders, on the other hand, help in dimensionality reduction, enabling the model to focus on essential patterns without losing critical information. By combining the strengths of these two approaches, your method provides an effective solution to a complex problem.
Problem Statement
Detecting facial keypoints is inherently complex due to the wide variability in human faces, such as differences in facial expressions, angles, lighting conditions, and occlusions (like glasses or facial hair). Traditional methods often struggle with achieving high accuracy in diverse environments, and the computational cost can be prohibitive for real-time applications. This paper tackles these challenges by leveraging deep learning techniques, particularly CNNs for feature extraction and Autoencoders for dimensionality reduction.
The Approach
Convolutional Neural Networks (CNNs) are widely acknowledged for their ability to capture spatial hierarchies within images. CNNs excel at recognizing patterns and features across varying scales and orientations, making them ideal for facial keypoint detection. In this study, CNNs are utilized to automatically learn and extract relevant features from input images. These features are passed through a series of convolutional layers that progressively abstract the facial image's key characteristics.
Autoencoders, another critical component of the model, contribute to dimensionality reduction. An Autoencoder is a type of neural network that aims to learn efficient representations of data by compressing input data into a lower-dimensional form (encoding) and then reconstructing it (decoding). The use of Autoencoders in this paper allows the model to focus on essential patterns and features of the face while discarding unnecessary details, thereby improving the model’s performance without sacrificing accuracy. The combined power of CNNs and Autoencoders leads to a model that can effectively and efficiently detect facial keypoints with greater accuracy and reduced computational overhead.
Dataset and Preprocessing
The paper discusses in detail the dataset used for training the model, which consists of labeled facial images with annotated keypoints. The images undergo several preprocessing steps to improve the quality of the input data and ensure the robustness of the model. These steps include image normalization, which adjusts the pixel values to a common scale, and data augmentation, which artificially increases the dataset by applying transformations like rotation, flipping, and zooming to the original images. These preprocessing techniques ensure that the model is capable of handling various real-world conditions, such as changes in lighting, angles, and expressions.
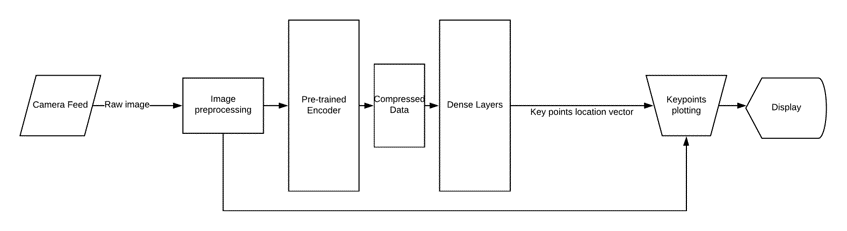
Model Architecture and Training
The proposed architecture incorporates multiple convolutional layers followed by pooling layers, which progressively reduce the spatial dimensions of the feature maps while retaining the most important features. The Autoencoder is introduced to compress the high-dimensional data into a more compact form, which is then passed through a fully connected layer to predict the keypoints' coordinates.
The model is trained using a loss function that minimizes the difference between the predicted keypoints and the ground truth annotations. The use of advanced optimization techniques, such as Adam, ensures faster convergence and better generalization across the dataset. The training process is also regularized using dropout to prevent overfitting, ensuring the model performs well on unseen data.
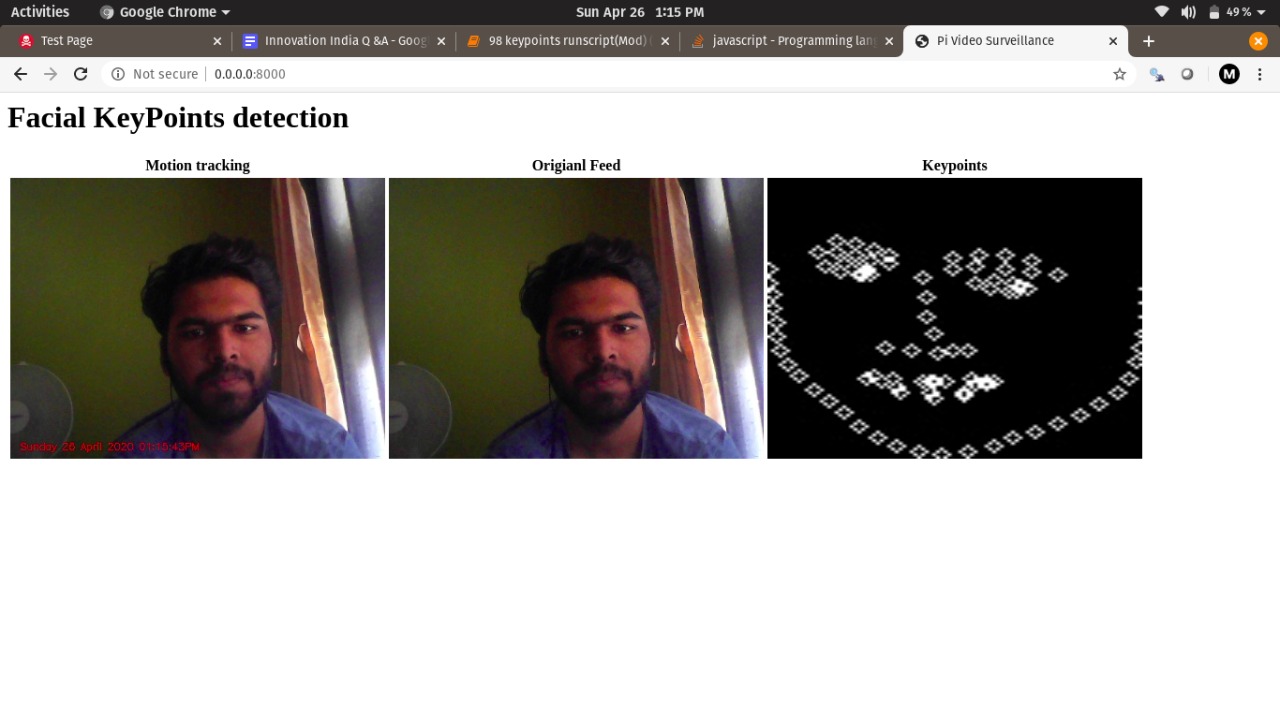
Result and Conclusion
The experiments conducted in this paper demonstrate a significant improvement in both accuracy and computational efficiency compared to traditional methods of facial keypoint detection. The combination of CNNs and Autoencoders proves to be highly effective in capturing the nuances of facial structures, leading to precise keypoint localization. Furthermore, the model exhibits strong generalization capabilities, performing well on new images that it has not encountered during training.
The practical implications of this research are vast. Facial keypoint detection is a foundational technology in several domains, including biometric authentication, interactive gaming, augmented reality, and even healthcare. For instance, the accurate detection of facial keypoints can be used to monitor patients' facial movements for medical diagnosis or rehabilitation. In augmented reality, precise keypoint detection enhances the realism and interactivity of applications that overlay virtual elements onto real-world faces.
You can check the paper below or at the conference link
© 2024 Ankit Sinha & Author of the above mentioned paper. All content, including images, is either created or owned by me. Unauthorized use is prohibited.