
AI Learns to Battle Poke ́mon

- By Ankit Sinha & Zach Raffo
- Project Paper can be given on request (Email)
Abstract
The Poke ́mon battle system, as featured in the video game series and popularized further through platforms like Poke ́mon Showdown, has evolved into a highly competi- tive arena where players continuously strategize to outma- neuver each other. In this work we investigate the feasi- bility of leveraging artificial intelligence (AI) to engage in Poke ́mon battles autonomously, with a focus on learning op- timal strategies. The research investigates the use of Deep Q Learning Networks (DQN) and Proximal Policy Opti- mization (PPO). Through these algorithms, AI agents are trained to maximize rewards by winning battles, fainting en- emy Poke ́mon, and securing opponent Poke ́mon, while be- ing penalized for losses and adverse outcomes. The com- plexity of Poke ́mon battles lies in the multitude of fac- tors involved, including Poke ́mon attributes, move sets, and stochastic elements, which pose challenges in defining an ef- fective state representation for the algorithms. By investigat- ing DQN and PPO algorithms, this study aims to shed light on the capabilities of AI in learning and mastering Poke ́mon battles, while also uncovering insights into popular strate- gies employed in the competitive Poke ́mon gaming commu- nity. Through training autonomous Pokemon playing agents against rule-based bots, we found that both DQN and PPO are viable approaches to solving Poke ́mon battles, and that their performance can be improved through structuring re- wards. With the best configuration of rewards and training against a strategic opponent, DQN and PPO agents achieved 77.5% and 73.5% win rates against the most challenging op- ponent.
Results
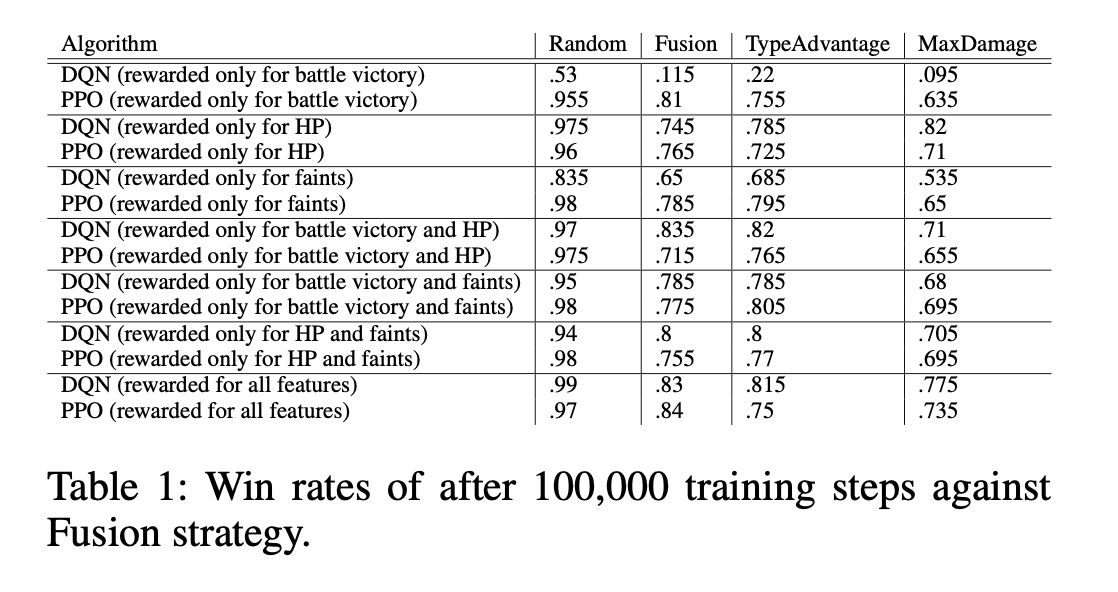
We aimed to incentivize desirable behaviors and strate- gic decision-making while penalizing unfavorable outcomes to guide the RL agent toward learning effective battle strategies. Through experimentation and fine-tuning, we be- lieve that this reward structure provides a balanced initial framework for training RL agents to become competitive Poke ́mon players, capable of navigating the complexities of Poke ́mon battles. We measured performance by win rate and tabulated the results for each algorithm evaluated against each baseline listed in Table 1.
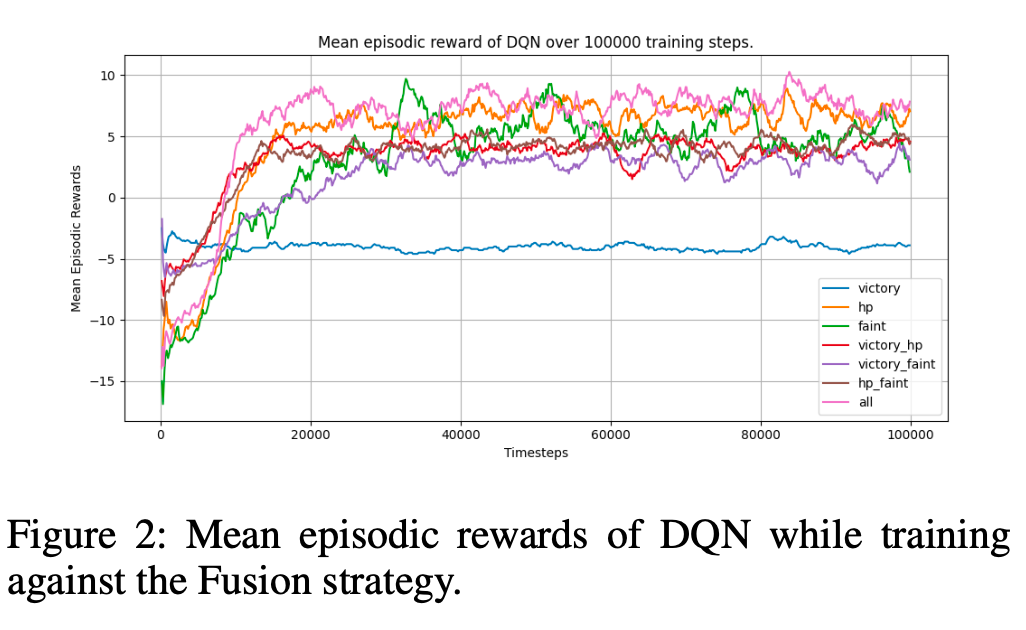
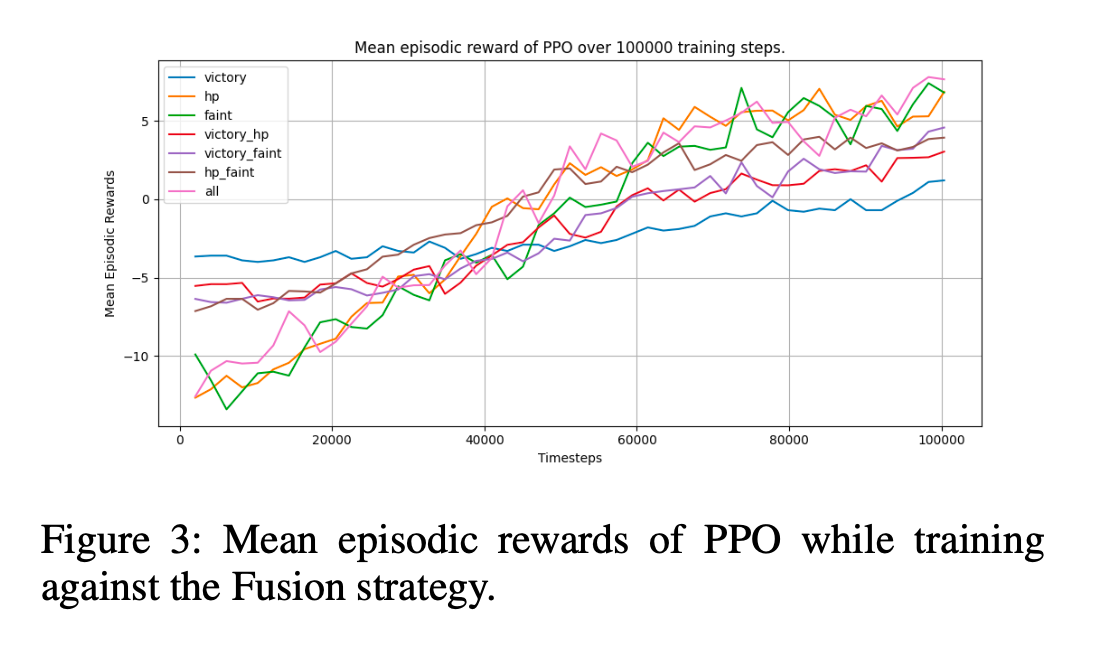
DQN vs. PPO For both DQN and PPO, the average win rate against all opponents was greatest when all features were taken into consideration when calculating rewards. The mean episodic rewards achieved by DQN and PPO agents are shown in figures 2 and 3. DQN showed the most growth in the first 20,000 training steps, and failed to improve much in the next 80,000. PPO on the other hand displayed a slower but smoother trend, which is expected due to its clipped sur- rogate objective function.
While DQN converges faster than PPO, PPO seems to po- tentially have a higher ceiling if trained for more steps. This may be the subject of future research.
Rewards The impact of changing how rewards are struc- tured significantly impacted the final performance of both algorithms. The inclusion of HP and fainting is important, as can be seen in figures 2 and 3, especially for DQN. When only rewarding battle victory, DQN performed slightly bet- ter than a strategy making random moves every turn. The inclusion of HP made a huge change for DQN because HP is directly related to the immediate outcome of the battle.
Conclusion
In conclusion, while representing the state space compre- hensively is difficult due to the battle mechanics and the dy- namic nature of the gameplay, we believe our results show that DQN and PPO are both viable approaches to solv- ing Poke ́mon battles when using a simple state embedding. Also, their performance can be improved through structuring rewards intelligently using domain knowledge. Additionally, PPO may outperform DQN when trained over a longer pe- riod of time.
Structuring rewards The success of RL algorithms in mastering Poke ́mon battles hinges on appropriately design- ing the reward structure. Shaping rewards to incentivize de- sired behaviors while discouraging undesirable ones is es- sential, but requires a deep understanding of game dynamics and strategic subtleties.
Nevertheless, despite these challenges, RL holds promise as a tool for developing competitive Poke ́mon players. With further research and development, RL-based approaches have the potential to evolve into formidable opponents against human players. This research not only contributes to the development of AI agents capable of mastering intricate games like Poke ́mon but also sheds light on fundamental questions about artificial intelligence, learning, and strategic behavior.
References
Brown, N.; Lerer, A.; Gross, S.; and Sandholm, T. 2018. Deep Counterfactual Regret Minimization. CoRR, abs/1811.00164.
Lanctot, M.; Waugh, K.; Zinkevich, M.; and Bowling, M. 2009. Monte Carlo Sampling for Regret Minimization in Extensive Games. 1078–1086.
Mnih, K. K. S. D. e. a., V. 2015. Human-level control through deep reinforcement learning. 529–533.
Moravc ́ık, M.; Schmid, M.; Burch, N.; Lisy ́, V.; Morrill, D.; Bard, N.; Davis, T.; Waugh, K.; Johanson, M.; and Bowling, M. H. 2017. DeepStack: Expert-Level Artificial Intelligence in No-Limit Poker. CoRR, abs/1701.01724.
Sandholm, T. 2015. Abstraction for solving large incomplete-information games. Proc. Conf. AAAI Artif. In- tell., 29(1).
Schulman, J.; Wolski, F.; Dhariwal, P.; Radford, A.; and Klimov, O. 2017. Proximal Policy Optimization Algorithms. CoRR, abs/1707.06347.
Silver, D.; Huang, A.; Maddison, C. J.; Guez, A.; Sifre, L.; van den Driessche, G.; Schrittwieser, J.; Antonoglou, I.; Panneershelvam, V.; Lanctot, M.; Dieleman, S.; Grewe, D.; Nham, J.; Kalchbrenner, N.; Sutskever, I.; Lillicrap, T.; Leach, M.; Kavukcuoglu, K.; Graepel, T.; and Hassabis, D. 2016. Mastering the game of Go with deep neural networks and tree search. Nature, 529(7587): 484–489.
Vinyals, O.; Babuschkin, I.; Czarnecki, W. M.; Mathieu, M.; Dudzik, A.; Chung, J.; Choi, D. H.; Powell, R.; Ewalds, T.; Georgiev, P.; Oh, J.; Horgan, D.; Kroiss, M.; Danihelka, I.;
Huang, A.; Sifre, L.; Cai, T.; Agapiou, J. P.; Jaderberg, M.; Vezhnevets, A. S.; Leblond, R.; Pohlen, T.; Dalibard, V.; Budden, D.; Sulsky, Y.; Molloy, J.; Paine, T. L.; Gulcehre, C.; Wang, Z.; Pfaff, T.; Wu, Y.; Ring, R.; Yogatama, D.; Wu ̈nsch, D.; McKinney, K.; Smith, O.; Schaul, T.; Lillicrap, T.; Kavukcuoglu, K.; Hassabis, D.; Apps, C.; and Silver, D. 2019. Grandmaster level in StarCraft II using multi-agent reinforcement learning. Nature, 575(7782): 350–354.
Zinkevich, M.; Johanson, M.; Bowling, M.; and Piccione, C. 2008. Regret minimization in games with incomplete information. Advances in Neural Information Processing Systems, 20: 905–912.