
AI Learns Pokemon Battle - II

Exploring Reinforcement Learning in Advanced Pokémon Battles, This is a project continuing the previous project
Project Paper can be given on request (Email:[email protected])
Abstract
This study explores reinforcement learning (RL) in Pokémon battles, focusing on Proximal Policy Optimization (PPO), Deep Q-Networks (DQN), and Asynchronous Advantage Actor-Critic (A3C). Using a Markov Decision Process (MDP) framework, agents were trained in simulated environments to handle advanced battle mechanics like Dynamax and Terastalization. Results revealed A3C's adaptability in complex setups, outperforming DQN and PPO in dynamic environments.
Introduction
With evolving battle mechanics in Pokémon games, AI agents face increasingly complex challenges. This project integrates:
- Advanced State Representations: Capturing dynamic conditions and opponent strategies.
- Adaptive Rewards: Aligning AI behavior with strategic goals.
- Dynamic Policy Learning: Iterative refinement of strategies.
Tools like `poke-env` and Pokémon Showdown facilitated simulations, providing diverse scenarios for RL evaluation.
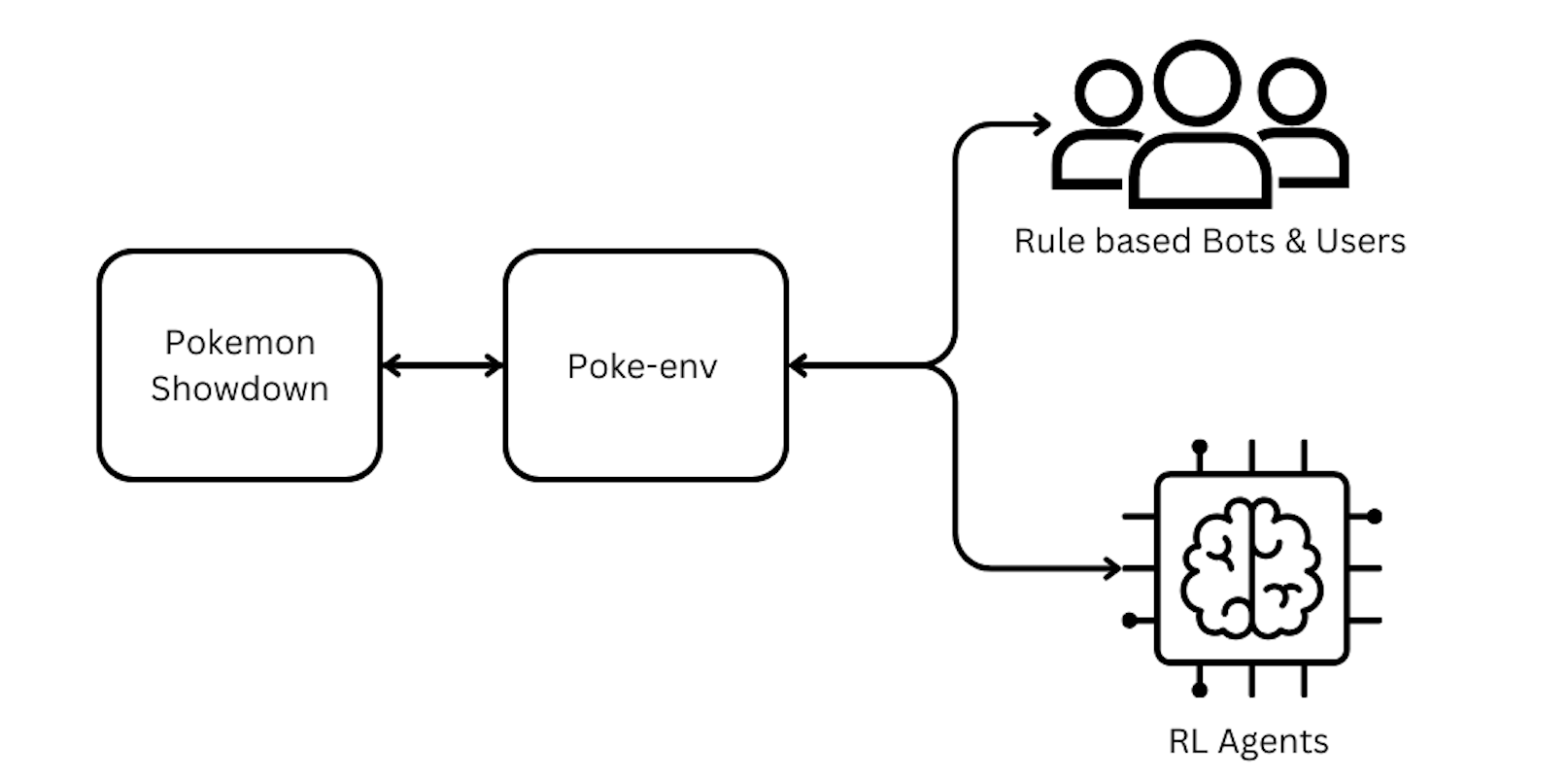
Algorithms
The methods that were used and experimented on

1) Deep Q-Networks (DQN)
DQN is a value-based reinforcement learning algorithm that uses a neural network to approximate the optimal action-value function. It learns by maximizing the cumulative reward for each state-action pair in an environment modeled as a Markov Decision Process (MDP).
- Strengths: Quick convergence in simpler environments, where deterministic and straightforward decision-making suffices.
- Performance: Achieved a 77.5% win rate against bots in environments with basic battle mechanics. However, its adaptability to complex scenarios was limited due to the simplicity of its value-based approach.
2) Proximal Policy Optimization (PPO)
PPO is a policy-based RL algorithm that directly optimizes the policy, ensuring stability through a clipped surrogate objective function. It performs well in environments with high-dimensional action spaces by iteratively updating the policy based on collected experiences.
- Strengths: Stable learning and consistent performance in varied environments.
- Performance: Demonstrated moderate success in handling new mechanics like Dynamax and Terastalization, achieving a peak win rate of 38.69%. Despite this, it struggled with the added randomness and strategic depth of Terastalization.
3) Asynchronous Advantage Actor-Critic (A3C)
A3C combines the advantages of value-based and policy-based methods by utilizing a parallelized training approach. Multiple workers asynchronously update a global model, enhancing exploration and accelerating learning.
- Strengths: Handles large state-action spaces effectively, excels in dynamic, multi-agent scenarios, and demonstrates robustness in learning from complex environments.
- Performance: Adapted well to the added complexities of Pokémon battles, showing steady improvement in reward accumulation and achieving competitive win rates in high-complexity scenarios.
Key Result
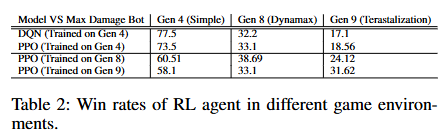
Dynamax & Terastalization Mechanics
These battle mechanics introduced significant complexity to the environment by altering the available actions and their strategic implications:
Dynamax: Allowed Pokémon to access powerful "Max Moves," temporarily boosting their stats and changing gameplay dynamics.
Terastalization: Enabled Pokémon to transform into a Tera type, altering type advantages and enhancing strategic depth.
Performance Insights:
- Reward structures play a critical role in guiding the agents toward effective strategies. Incorporating health points (HP) and fainting status into the rewards significantly improved learning outcomes.
- Training environments also influenced performance. Agents trained against strategically advanced bots (e.g., Max Damage bots) exhibited better long-term strategic development, even if their immediate win rates were lower.
- A3C’s parallel exploration and dynamic updates were particularly effective in exploring the expanded state-action spaces introduced by the new mechanics.
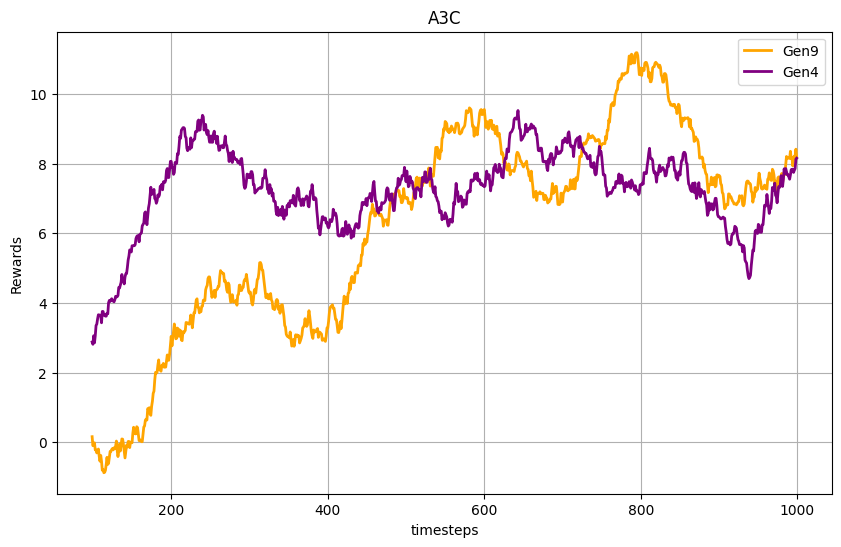
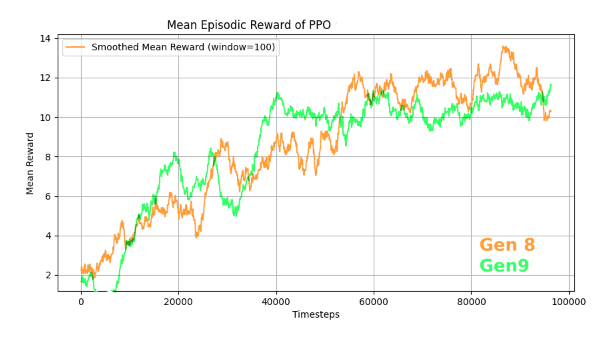
A3C Experimentation
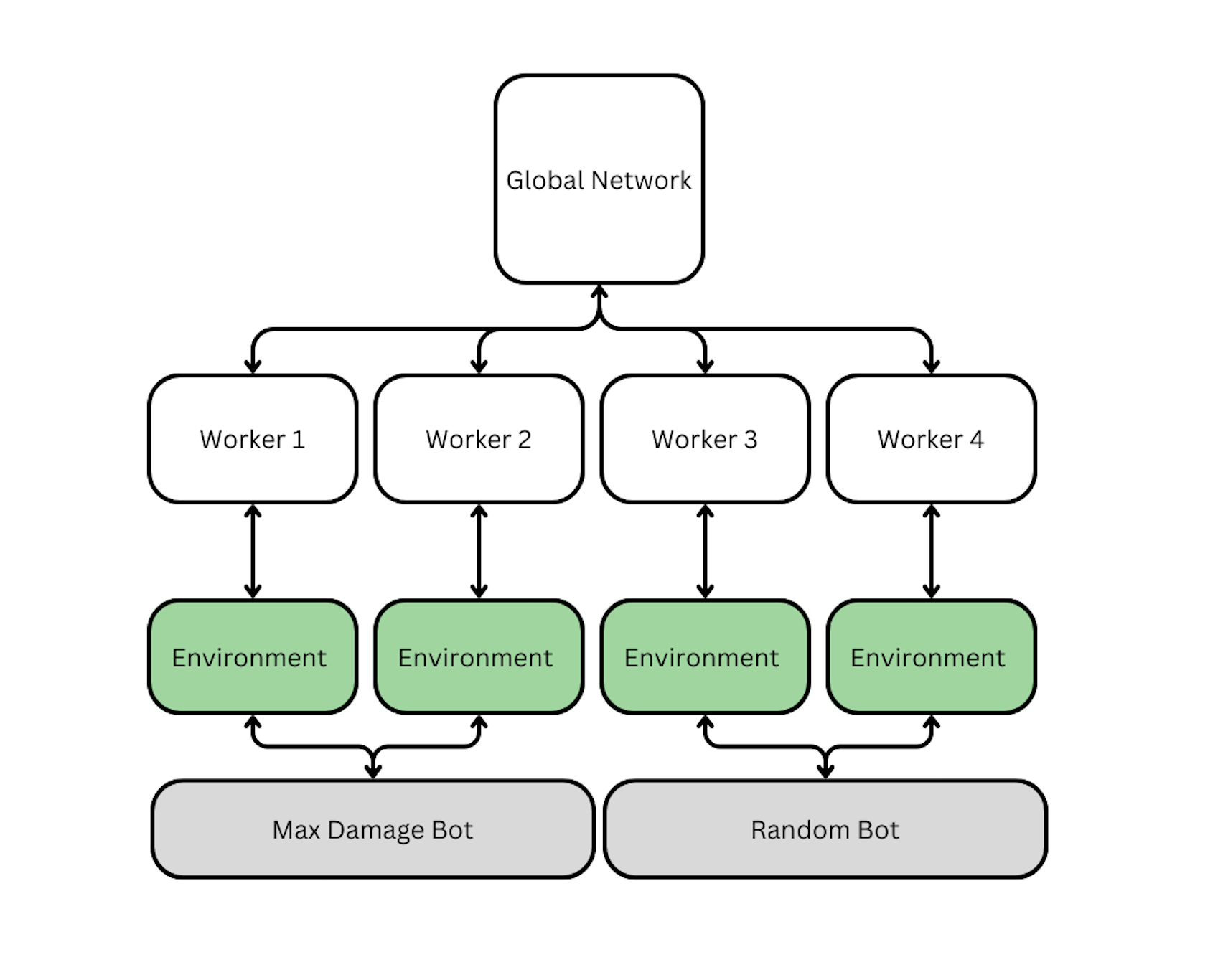
I enhanced the A3C implementation to train agents in parallel across multiple environments, where each environment featured battles against a different rule-based bot. These bots included Max Damage, Type Advantage, Random, and Fusion bots, each designed to simulate unique strategic challenges. This modification aimed to mimic the diversity of training against human opponents by exposing the A3C agents to varied strategies and decision-making patterns.
The parallel training setup allowed the A3C algorithm to learn from a wide spectrum of gameplay styles simultaneously, encouraging adaptability and robustness. By interacting with these distinct rule-based bots in parallel, the agents developed a more generalized and competitive approach to decision-making, aligning with the unpredictability and strategic diversity of human gameplay.
Experimental Setup
- Environment Configuration:
- Battles were modeled as Markov Decision Processes (MDPs) with dynamic state representations including move attributes, damage multipliers, and fainting statuses.
- The poke-env library and Pokémon Showdown were used to simulate battles with diverse strategic scenarios. - Training Framework:
- A3C agents were trained in parallel across multiple environments using asynchronous updates to a shared global model.
- Each worker explored independently, providing a diverse set of experiences for the global model and enhancing exploration and sample efficiency. - Training Parameters:
- Training spanned 1,000 episodes, with each episode comprising 30 timesteps
- Rewards were structured to incentivize battle victories, opponent HP reduction, and fainting outcomes.
Results:
This modified A3C implementation has shown promising signs of learning, as agents demonstrate adaptability to diverse strategies. However, achieving more robust and generalized learning outcomes requires running the training for longer episodes. The unorthodox approach of training against multiple rule-based bots in parallel introduces several challenges that need to be addressed:
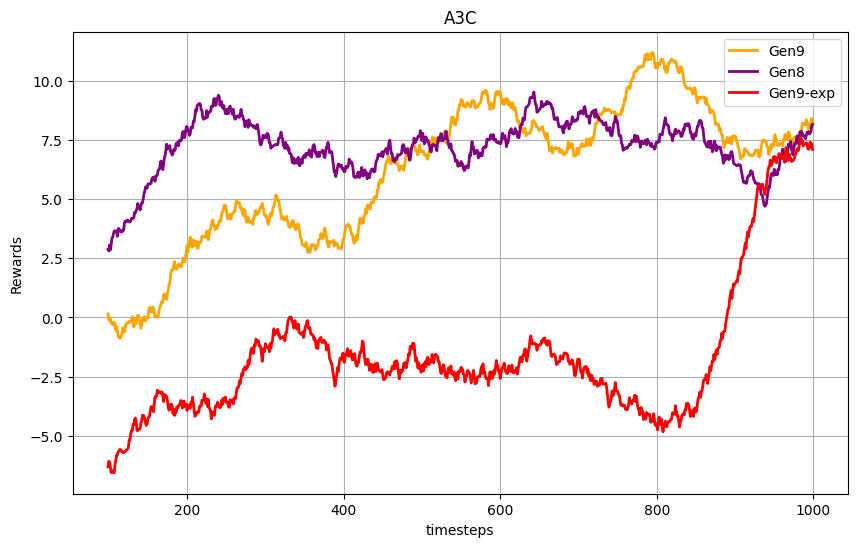
Challenges with the Current Approach
- Convergence Instability:
The asynchronous updates from environments featuring different bots (Max Damage, Type Advantage, Random, and Fusion) can introduce significant variance in the gradient updates. This may lead to instability in policy convergence, requiring careful tuning of learning rates and synchronization mechanisms. - Reward Signal Complexity:
Each rule-based bot represents a unique playstyle, making it challenging to design a unified reward signal that effectively guides the A3C agents across all scenarios. Misaligned or conflicting reward signals can hinder consistent policy improvement. - Exploration vs. Exploitation Trade-Off:
Training against diverse bots can increase the exploration of the state-action space, but it may also lead to suboptimal exploitation of learned strategies, particularly when agents are exposed to less common scenarios. - Computational Overhead:
Running parallel environments with different bots requires significant computational resources. The increased workload can result in bottlenecks, especially when scaling the number of parallel workers or extending the training duration. - Human-Like Generalization:
While training against bots aims to mimic human-like gameplay diversity, the deterministic or predefined nature of rule-based bots may limit the agents’ ability to generalize to unpredictable human strategies effectively.
Challenges and Future Work
- Reward Redesign:
The current reward functions lack the granularity and alignment necessary to guide agents effectively through the strategic complexities of Dynamax and Terastalization mechanics. Future work should focus on:- Dynamic Rewards: Tailoring rewards to better reflect the intricacies of gameplay, such as rewarding actions that maximize long-term advantages or counter specific strategies.
- Event-Based Feedback: Incorporating finer-grained feedback mechanisms, such as rewarding optimal usage of unique mechanics like Dynamax or Terastalization at critical battle moments.
- Multi-Objective Optimization: Balancing multiple objectives, such as maximizing damage, minimizing HP loss, and predicting opponent behavior.
- Advanced A3C Modifications:
Enhancing the A3C framework to handle the growing complexity of Pokémon battles may involve:- Hierarchical Learning: Decomposing complex tasks (e.g., deciding moves and utilizing mechanics) into simpler sub-tasks that can be tackled independently, enabling more structured learning.
- Action-Space Decomposition: Dividing the decision-making process into separate components, such as move selection, type transformation (Terastalization), and strategic switches, to reduce cognitive overhead.
- Meta-Learning: Incorporating meta-learning techniques to help agents quickly adapt to new opponents and strategies with limited training.
- Scalability:
To broaden the applicability of the framework, efforts should aim to:- Support multi-agent interactions to simulate more dynamic team battles and cooperative scenarios.
- Integrate additional battle features, such as weather conditions, terrain effects, and status-altering strategies, to further challenge and refine the agents.
- Explore scalable architectures that can efficiently handle the increased computational demands of expanded state-action spaces.
- Comparative Studies:
Comprehensive evaluations against state-of-the-art algorithms and hybrid approaches are essential for benchmarking. This includes:- Comparing A3C with newer methods like Soft Actor-Critic (SAC), Twin Delayed Deep Deterministic Policy Gradient (TD3), or other advanced reinforcement learning frameworks.
- Evaluating performance across varied gameplay environments, from simpler mechanics to highly dynamic setups featuring real-time interactions.
- Real-World Applications:
The insights from this study have broader implications and could be extended to:- Robotics: Applying reinforcement learning in tasks requiring precise sequential decision-making, such as robotic manipulation or navigation.
- Adaptive AI Systems: Enhancing AI capabilities in uncertain and dynamic environments, including financial modeling, logistics optimization, and healthcare decision systems.
- Gaming AI: Improving non-player characters (NPCs) in turn-based and real-time strategy games to provide more challenging and engaging experiences for players.
Conclusion
This study demonstrates the significant potential of the Asynchronous Advantage Actor-Critic (A3C) algorithm in navigating high-complexity environments, such as Pokémon battles with advanced mechanics like Dynamax and Terastalization. The experimentation showcased A3C's robustness and adaptability, leveraging asynchronous updates and parallel exploration to effectively handle dynamic and diverse strategies.
While the results highlight A3C's strengths, they also underline the importance of refining reward structures, extending training durations, and incorporating innovative modifications to address challenges posed by dynamic mechanics and unorthodox training setups. These findings provide a foundation for further advancements in reinforcement learning (RL), both in gaming and broader real-world applications.
Broader Impact
This work bridges theoretical advancements in RL with practical implementations in turn-based strategy games. The insights gained from this study can inspire future research in:
- AI in Gaming: Enhancing non-player characters (NPCs) for dynamic, human-like interactions.
- Adaptive Systems: Developing intelligent agents for dynamic decision-making tasks in robotics, healthcare, and financial modeling.
- Multi-Agent Environments: Expanding RL frameworks to incorporate collaboration and competition in multi-agent systems.
Code Repository: Explore the complete implementation, training data, and results at GitHub - AI Learns Pokémon Battle.
© 2024 Ankit Sinha. All content, including images, is either created or owned by me. Unauthorized use is prohibited.